Error Tolerant検索(拡張2段階検索)が統計的有意性を示すよう改善されました
Mascot Server の最新版 ver.2.8では、Error Tolerant検索(拡張2段階検索)にいくつかの重要な仕様変更がされています。まず、2段階目の検索結果にも、信頼度を反映する「期待値」が表示されるようになりました。これらの値は、カウント試行に基づく推定値であり、Decoyデータベースの検索を経て計算されます。
これまであまりError Tolerant検索をご利用になられたことがなかった方も、これを機に試してみてはいかがでしょうか。Errror Tolerant検索、拡張した探索で考慮できるのは次の3つ、1)想定外の修飾の可能性、2)ペプチドの1残基置換[SNPs]、3)ペプチドの非特異的切断、です。MASCOTでそれらを見つけるためにはError Tolerant検索が最も効率的な方法です。使用するには、検索パラメータの設定時に”error tolerant”項目にチェックを入れるだけです。MASCOT側での検索のステップですが、まず検索フォームで指定した検索パラメータを使って1回目の通常検索が行われます。1回目の検索の結果から、何かしらの同定ペプチドがアサインされているデータベースエントリすべてを対象に、検索対象を拡張した2段階目の検索が行われます。最初の検索で同定基準に満たなかったすべてのqueryについて、先ほど挙げた3要素、1)最初の検索でvariable modificationsとして指定しなかったすべての修飾について、いずれか1つ付与するパターン、2)残基置換マトリックスを使ったSNPs探索、3)”semi”設定、すなわち片側が任意の箇所で切れもう片方が指定した酵素特異性で切断されたペプチド、を考慮した検索されます。2段階目の検索が完了すると、両方の検索結果を1つにまとめたレポートが作成されます。
Mascot Server 2.8では、このError Tolerant検索に対して、検索パラメータのうち2つをError Tolerant 検索でも関連付けて使用する事ができるようにしています。その1つめは「Decoy」データベースの使用です。Decoyの指定を行わない場合、同定基準値並びに表示される期待値は、試行回数(訳者注:MASCOT MIS検索場合、ペプチド質量の条件をもとに絞り込まれテストされた候補ペプチドの数)から算出されますが、この推定方法は必ずしもいつも有効であるとは限りません。特に、データベースや検索パラメータに何か問題がありマッチング可能性を不当に多く考慮しているケースでは、同定基準値があまり正確でない事があります。Decoyデータベースを使った検索は検索時間が2倍になりますが、FDRによる外挿的で統計的な検証が加味された結果となります。
もう1つの新たな要素はFDRの指定値です。ペプチドの同定基準として使用され、2段階目の検索で対象となるタンパク質の選定にも影響を与えます。例えば5%のFDRで有意なペプチドを同定していたケースでは500のタンパク質を2段階目の検索に送っていたケースが、FDRを1%など厳しくする事で対象タンパク質が400に減る、といったような具合です。なお検索後の結果表示画面の段階でFDRを再調整することはできますが、検索の最初にFDRを設定した場合と完全に同じ結果にはならないのでその点にご注意ください。(訳者注: 後でFDRの設定値を変えても2段階目の検索をやり直すことはなく、あくまでも最初に行った検索結果の再構成だけが行われます。)
Target、Decoy双方のタンパク質はペアとして扱われます。1回目の検索結果を受けてタンパク質が選別されますが、2段階目の検索ではそのタンパク質のTargetタンパク質とDecoyタンパク質のペアがともに採用され検索に利用されます。1回目の検索で利用されたDecoyデータベースはTargetから作成された、同一サイズのデータベースであり、2回目の検索で利用されるものもやはりTargetとDecoyが同一の性質を持つことになります。指定したFDR値は、1回目の検索と2段階目の検索結果それぞれに適用されます。MASCOTでは基本的にPSMの数をカウントしてFDR計算に利用しており、それぞれの結果で指定FDRの条件を満たすのであれば、結合された結果でも必ず基準を満たします。
あるクエリが1回目の検索で同定基準を満たした場合その結果がそのまま報告され、2段階目の検索は行われません。2段階目の検索で真の答えが見つかるケースを見逃す事になりますが、最初の結果を信じる方が統計に誠実であるという考えです。例えば1回目の検索で特定のクエリの同定基準値40に対しスコア52のマッチが得られ、2段階目の検索でスコア80のマッチが得られたとしても1回目の結果を使用する事になります。この方針について気になる方がいらっしゃるかもしれません。すべて2回目の検索で評価する従来の方法と比較しても一長一短があります。マイナスになるケースの例ですが、1回目の検索ではスコア52で基準を超えていたペプチドが、2回目の検索で検索空間が広がる事で同定基準値が55になって同定基準を超えなくなってしまう、といったようなケースです。勝つこともあれば、負けることもあるという事です。総合的な観点から今回の仕様を選択しています。
ErrorTolerant検索の実例として、グラーツ医科大学で取得され、PRIDEプロジェクトPXD002726で公開されているLTQ-Orbitrap Velosデータの検索結果を取り上げました。詳細は以前のブログ記事(英語版)を参照してください(検索結果はこちらです)。
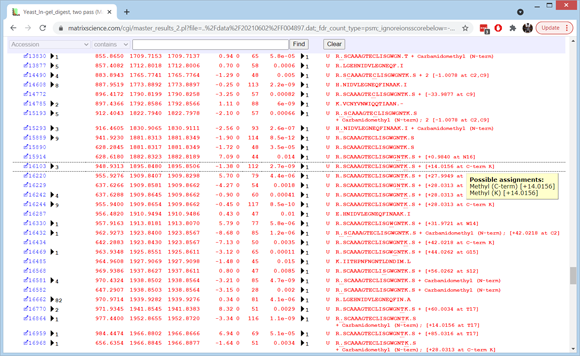
検索パラメータは、結果画面上部ヘッダーの関連部位をクリックして展開することで確認できます。また、手元のサーバーにあるUnimodデータの構成、Error Tolerant検索に使用される修飾の組み合わせを確認しておく事も重要です。今回のケースではunimod定義ファイルについて最新の更新版を利用しましたが、独自の追加条件として、「同位体ラベル」と分類している項目並びに1000 Daを超える質量を持つ修飾は2段階目の検索で使用する修飾リストから除外するよう設定しています。対象の修飾は元々の1499から1045に減っています。
結果画面の中にある”Sensitivity and FDR”のセクションをクリックして拡大すると、PSMの1% FDRでの同定数が4279であることがわかります。一方 protein FDRはあまりよくありませんが、これは42個のDecoy PSMが20個のDecoy タンパク質にランダムに散らばっていることに起因します(訳者注:Protein FDRは、分母であるTargetの同定タンパク質数が少ない場合、今回のように極端に値が大きくなってしまう事があります。1%単位の議論をするのであれば、分母の数字は最低100必要です。FDRを論ずるときには分母の数に注意です。このようなケースでは無理にprotein FDRを使用しないか、次の記述を参考にしてください)。タンパク質の同定に必要なユニークペプチド数を1から2に増やし、"Format"ボタンをクリックする事で、タンパク質のFDRはより満足のいく0%に下がります。
2回目の検索で追加の同定スペクトル(PSM、Peptide-Spectrum Matches)がいくつ得られたかを確認したい場合、Error Tolerant検索結果を含んだ結果と除いた結果とを比較する事ができます。初期表示でのPSM数(4279)をメモした後、表示オプションの「Error tolerant matches」を「None」に変更して「Format」を選択すると、PSM数は2972に下がり、1% FDR基準でError Tolerant検索の2段階目の検索により1307の新しいマッチがあるのがわかります。また、Error Tolerant検索で新たにピックアップされた内容についてもその概要を確認する事ができます。ヘッダーの「Modification statistics」セクションをクリックして展開すると、Error Tolerant検索で追加された修飾などの種類がわかる一覧が確認できます。Error Tolerantの結果を含む/含まない状態で見比べる事で追加された内容の構成もわかります。Error Tolerant検索結果でのリストを見ると、非特異的切断(Non-specific cleavage)が、脱アミド化、エチル化、メチル化、グアニジニル化と並んで、リストの最上位に位置しています。上位に挙がった修飾の項目のうち脱アミド化とグアニジニル化のほとんどは生体内の翻訳後修飾でなく、人工的な修飾です。また、トリプシンは自己分解を抑えるためにメチル化されているので、エチルのほぼ全ては実際にはジメチルでしょう。
上位10位までのタンパク質ファミリーの個々のペプチドマッチ詳細をまとめて見るには、ページ下部の「Expand all」をクリックしてください。最初のファミリーは、コンタミのヒトケラチンです。R.TSQNSELNNMQDLVEDYK.Kの行までスクロールダウンします。クエリ18970のメチオニン酸化のペプチドは1回目の検索で得られたマッチです。一方、クエリ18999の酸化および脱アミド化されたペプチドは2段階目の検索で得られたマッチです。どちらもスコアは99ですが、期待値を比較するとクエリ18970の結果(1.7e-10)はクエリ18999の結果(5.5e-8)より300分の1低く、それだけ検索空間が小さいことを反映しています。ランク列の値の上にカーソルを合わせると、同定基準値がクエリ18970の検索では18、クエリ18999の検索では39であることが確認できます。
今回ご紹介した解析データは人工的な修飾が多く、翻訳後修飾に焦点を当てた話にするには難しかったという意味では少々不適切ではありますが、少なくとも新機能がどのように機能するかをご理解いただく一助にはなるかと思います。より詳細な情報は、Error Tolerant検索のヘルプページを参照してください。
Keywords: delta mass, error tolerant, FDR, modification, statistics