DIAデータに対する、スペクトル中心方式・確率的スコアリング
DIA 解析では、同定されたタンパク質の数を最大化することに多くの注意が払われていますが、結果の質にはほとんど注意が払われていないように思われます。私たちはDIA データ解析に適用できる汎用的なスペクトラム中心方式の検索方式「Mascot DIA」に取り組んでいます。注目するべき点は、フラグメンテーションパターンに関して踏み込んだ処理を行わずシンプルにMS/MS スキャン内のすべてのピーク情報を使用することにあります。スペクトラム中心方式の検索とフラグメント質量マッチングの確率的スコアリングを組み合わせることで、ペプチド同定結果の信頼度が向上します。
Mascot DIA の仕組み
Mascot はスペクトラム中心方式の検索エンジンです。ペプチド中心方式との違いについては、以前のブログ「スペクトル中心方式のDIA解析の展望」 (The promise of spectrum-centric DIA ) で説明しておりますので詳細はそちらをご覧ください。
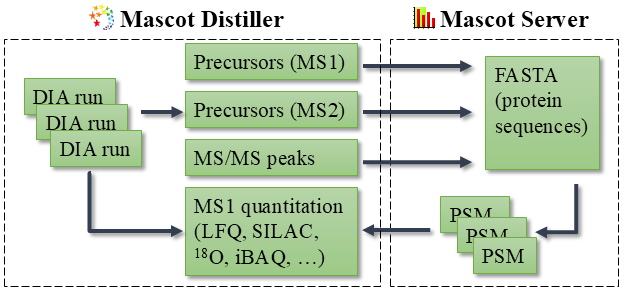
データベース検索はタンパク質データベースの配列から始まります。Mascot は配列から消化酵素による切断処理が行われたペプチドを作り、b や y イオン系列のような理論的フラグメント質量を計算します。ピーク強度の予測情報は利用していません。
続いてMS/MS スキャンにて測定されたピークを順次(強度の高いピークから)選択し、いくつかの指標を計算します。例えば、各イオン系列におけるマッチ数(a, b, c, x, y, z+1 …)、全体のマッチした残基の数、マッチしなかったピークの数などです。
なぜ確率的スコアリングが重要か?
確率的スペクトラム中心スコアリングには 2つの大きな利点があります:
1. MS/MS スペクトル中のすべての情報を使用する
本来3つから5つのフラグメントがマッチするだけのペプチドというのはランダムマッチレベルであり(p 値 = 1.0)、統計的に有意なスコアを得るには十分な配列カバレッジが必要です。Mascot はまた、脱水脱アミノ(例:y-H2O、b-NH3)のイオン系列や、フラグメントの ニュートラルロスピークも検索に利用します。これらの情報によりマッチングの信頼度を高めます。
2.フラグメント強度予測に依存しない
Mascot の確率的スコアリングは予測強度をまったく必要とせず、スコアリングにピークを選ぶ際に観測されたピーク強度を使うだけです。したがって、強度の変動(重い可変修飾の存在など)やランダムに欠けたピーク(ニュートラルロスなど)にも影響を受けません。十分な残基カバレージがあれば問題ありません。
さらに重要なのは、Mascot DIA では時間軸に沿ってスペクトルをデコンボリューションしたり、擬似 DDAプロジェクションを作成する必要がないということです。複数のペプチドからの理論フラグメントを、元の MS/MS スキャンに直接マッチングさせます。もしペプチドがうまくフラグメント化されていれば、そのフラグメントはすべて 1 つの MS/MS スキャンに含まれるため、隣接するスキャンを見る必要はありません。観測されたフラグメントをマッチさせ、スコアリングするだけです。
フラグメント化がうまくいっていないペプチドでは、ノイズや無関係なペプチドに混ざった数本のフラグメントピークしか得られない事もあるでしょう。そしてこれまで、非常に複雑なアルゴリズムや機械学習手法がこうしたペプチドを同定するために考案されています。しかし私たちのアルゴリズムでは設計上フラグメント化の不十分なペプチドを同定しないため、偽陽性をはじく事ができます。
ウィンドウ幅の狭い DIAデータのみ適用可能なのか?
一般的に、スペクトラム中心検索方式はウィンドウ幅の狭い DIA で有効な戦略です。ここでいう「狭い」とは 2〜8 Th の分離ウィンドウを意味します。しかしながら、データの質が疎なケース(例:シングルセル)や追加の分離次元(例:イオンモビリティ)が使われる場合、より広いウィンドウ幅でも適用できる可能性があります。
現在、機器の進歩に伴い分離ウィンドウ幅は狭くなり、スペクトルの複雑さは減少していると言えるでしょう。2018 年には既に Ludwig らが「DIA アルゴリズムはいずれ DDA アルゴリズムと収束する」と予測していました。現在では狭いウィンドウ幅の DIA が一般的であり、DIA スペクトルを解析するのに複雑なニューラルネットワークや DDA スペクトルライブラリは不要になりつつあります。
最近の Thermo Orbitrap Astral装置においても、非常に短い勾配時間の解析に向かう傾向が見られます。ペプチド中心方式の検索は通常、フラグメントピークの溶出プロファイルを追跡するために隣接するスペクトルスキャンの情報を使います。しかし勾配が 15 分以下になると、ペプチドは 1〜2 サイクルでしか観測されないかもしれません。もしフラグメントごとに 1〜2 回しか観測がないなら、ペプチド中心方式の検索は存続できるでしょうか?さらに、LC を完全に省略するダイレクトインフュージョンDIA ではどうでしょうか?
私たちは DIA 解析のため、確率モデルを 2 つの方法で最適化しました。1つはノイズモデルを改良し、無関係なペプチド由来ピークをより適切に扱えるようにした事、そしてもう1つは高い質量精度を持つ最新機器を活用できるようモデルをすべて見直した事です。
SCIEX TripleTOF 6600+、SWATH、ウィンドウ幅の狭いデータ解析
これを実際のデータを使ってご説明します。
以下の例は、Puyvelde ら (2022) による優れた DIA ベンチマークデータセット(PXD028375)から取られています。そこからLFQ_TTOF6600_SWATH_Condition_A_Sample_Alpha_01.wiff を選びました(選択の意図は特にありません)。これは SCIEX TripleTOF 6600+ で SWATH 99 可変ウィンドウを用いて取得されたものです。ウィンドウ幅は大部分が 6〜7 Thで、上側の質量領域では 12 Th に広がります。サイクル時間は 4 秒(MS スキャン 250ms、MS/MS スキャン 37.5ms)で、勾配は 2 時間です。(ウィンドウの設定スキームは論文の補足表 S3 に記載されています。)
この raw ファイルを、Mascot Distiller 最新版のベータバージョン(Precursor 検出に関する新機能を有しています)でピークリスト処理し、その後 Mascot Server 3.1(DDA スコアリング)と、新しい DIA スコアリングモデルを用いた最新版ベータバージョンで検索した結果を比較しました。他のパラメータ(データベース、フラグメント許容誤差、機器タイプなど)はすべて同一です。同定ペプチド数を下表にまとめています。
| Scoring | PSMs | Sequences | Protein hits |
|---|---|---|---|
| Mascot 3.1 (DDA) | 41,204 (0.49% PSM FDR) | 9,230 (1% seq FDR) | 2,070 |
| Mascot 3.2 beta (DIA) | 73,068 (0.33% PSM FDR) | 15,728 (1% seq FDR) | 3,136 |
ノイズモデルの改良により、同一の配列 FDR において統計的に有意なペプチド数はほぼ 2 倍になりました。分離ウィンドウ幅が狭く、勾配も長いため、スペクトルもあまり複雑ではありません。その多くは、1〜2 本のペプチド由来フラグメントしか含まない DDA スペクトルのように見えます。以下にMS/MS スキャン 103104を示します。同じスペクトルを、マッチング内容を確認する観点から3回表示しています。
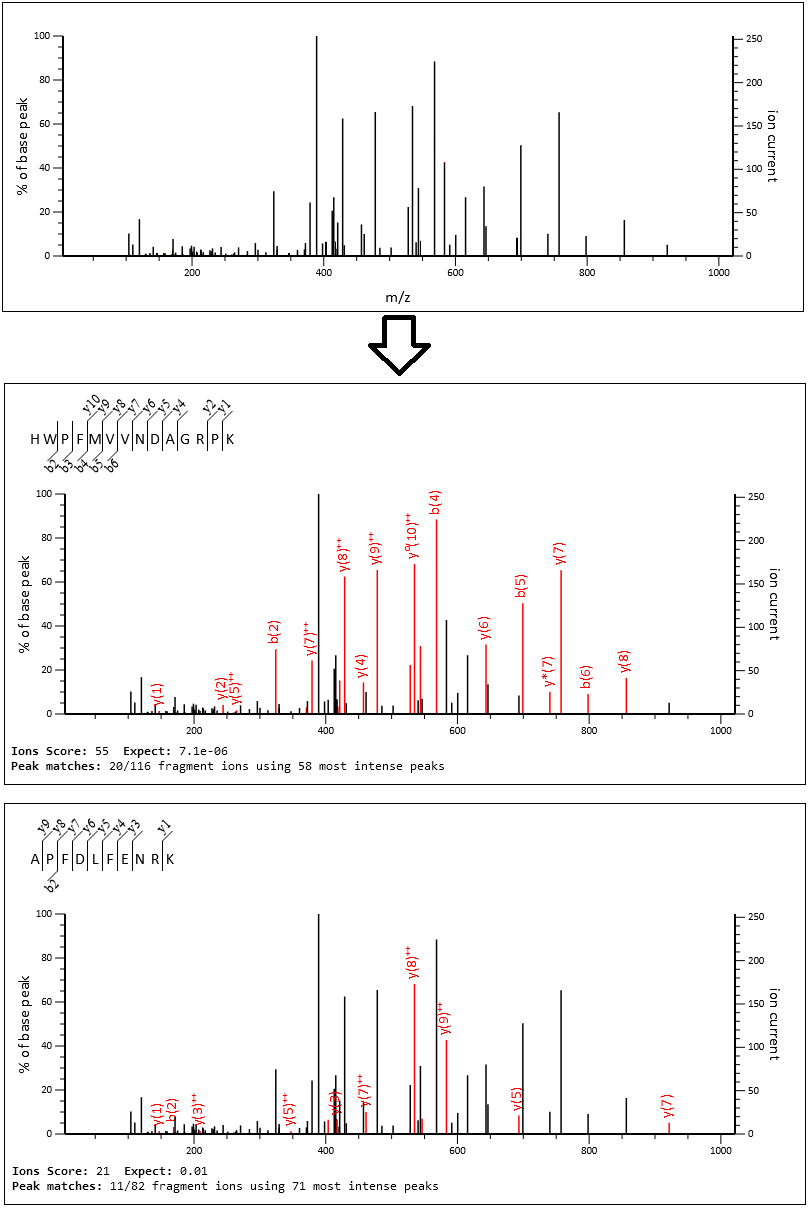
Mascot は HWPFMVVNDAGRPK(ヒートショックコグネートP11142 および E9PK54 に存在するペプチド)と APFDLFENRK(ヒートショックタンパク質 HSP 90-alpha P07900 に存在するペプチド)のフラグメントピークを同定し、どちらも非常に良好な残基カバレッジを示しました。y(1)、y(8)++、y0(10)++ のピークを除いて同じ値の質量はなく、また強度が高いほとんどのピークが理論値と紐づけされているため、このスペクトルにはこの2つ以外のペプチドが含まれる可能性は低いと考えられます。約 414 Da 周辺のピーク群はフラグメント化されていない 前駆体ペプチドピークです。また約 390Da付近にある非常に高いピークは 分離ウィンドウの外にあるため、説明できないノイズピークと考えられます。
スコアと Expect 値はスクリーンショット内に示されています。スコアは -10log10(p 値) であり、ここで重要なのは、pが理論質量と観測スペクトルの一致がどれだけランダムとは考えにくいかを測る指標であることです。p 値が非常に小さい(スコアが非常に高い)ということは、そのマッチがランダムである可能性が極めて低いという事を意味します。
新しい DIA スコアリングにより、ピークリストをさらに掘り下げて低強度ピークを選択できます。APFDLFENRK 理論値とのマッチングの場合、Mascot は他のペプチド由来の高いピークをすべて「ノイズ」として無視し、APFDLFENRK に無関係なものとして扱うことができました。
このように、Mascot DIA の確率的スペクトラム中心スコアリングは、シンプルで堅牢な枠組みで DIA データ解析の信頼性を大幅に高めることができます。