|
Minimally Invasive and Portable Method for the Identification of Proteins in Ancient Paintings
Paola Cicatiello, Georgia Ntasi, Manuela Rossi, Gennaro Marino, Paola Giardina, and Leila Birolo
Anal. Chem., 2018, 90, 10128-10133
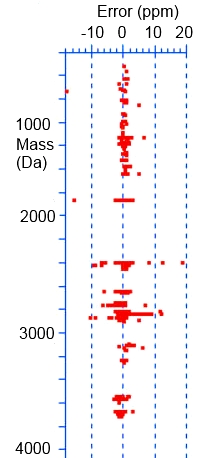
The authors have developed a method for capturing and identifying proteins from works of art in order to understand aging and deterioration in historical objects. Invasiveness of analytical measurements is a central issue in conservation and restoration of cultural heritage goods, and this method demonstrated no significant surface changes at the microscopic level.
The method uses a cellulose acetate sheet that is coated with Vmh2 hydrophobin, which then non-covalently immobilizes the trypsin enzyme. Dampened sheets are then gently put in contact with the artwork, removing the proteins and generating the peptides. Extraction of the peptides from the sheet is followed by MALDI-TOF MS and MS/MS analysis to identify the proteins.
Eight different historical samples were investigated, one from the detached frescoes by Buonamico Buffalmacco (XIII century) from the Monumental Cemetery in Pisa, and seven unknown painting from the XIX to XX centuries. The results on the Buffalmacco frescoes were in agreement with previously published results.
|